How to Create a Bagging Ensemble of Deep Learning Models in Keras
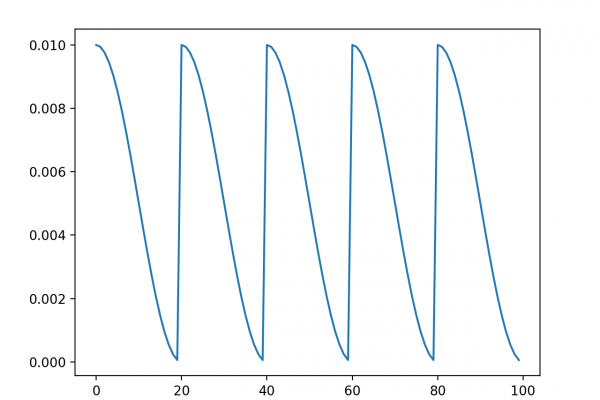
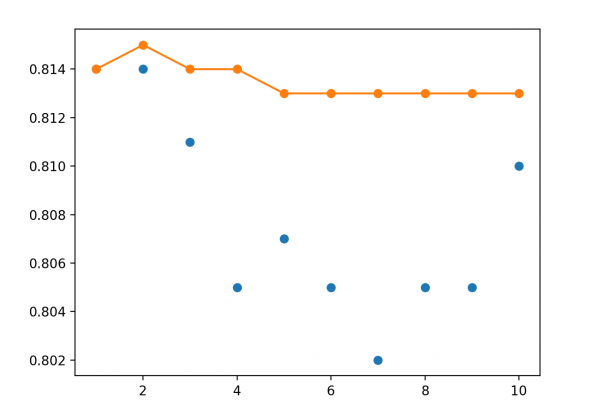
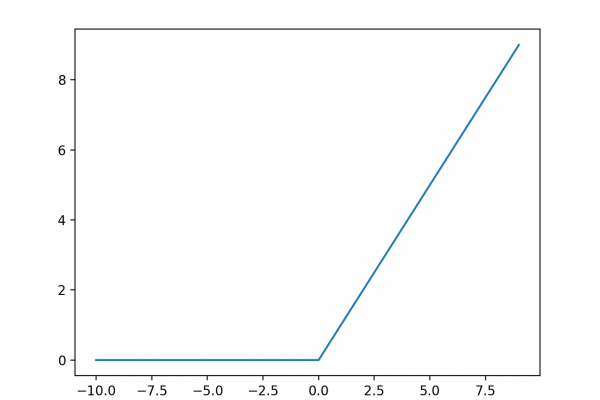
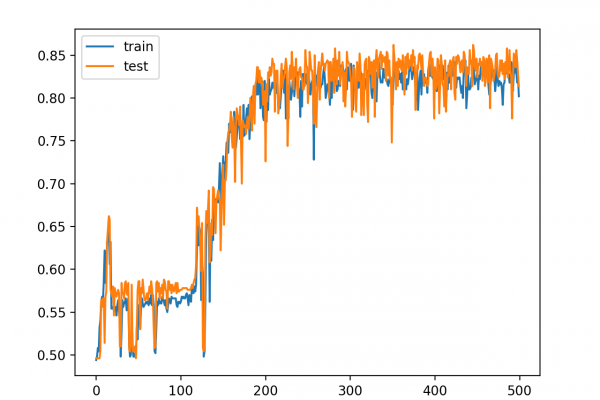
Last Updated on August 25, 2020 Ensemble learning are methods that combine the predictions from multiple models. It is important in ensemble learning that the models that comprise the ensemble are good, making different prediction errors. Predictions that are good in different ways can result in a prediction that is both more stable and often better than the predictions of any individual member model. One way to achieve differences between models is to train each model on a different subset […]
Read more