Impact of Dataset Size on Deep Learning Model Skill And Performance Estimates
Last Updated on August 25, 2020
Supervised learning is challenging, although the depths of this challenge are often learned then forgotten or willfully ignored.
This must be the case, because dwelling too long on this challenge may result in a pessimistic outlook. In spite of the challenge, we continue to wield supervised learning algorithms and they perform well in practice.
Fundamental to the challenge of supervised learning, are the concerns:
- How much data is needed to reasonably approximate the unknown underlying mapping function from inputs to outputs?
- How much data is needed to reasonably estimate the performance of an approximate of the mapping function?
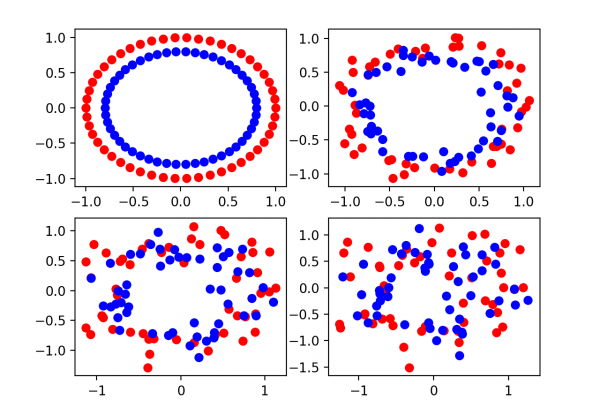
Generally, it is common knowledge that too little training data results in a poor approximation. An over-constrained model will underfit the small training dataset, whereas an under-constrained model, in turn, will likely overfit the training data, both resulting in poor performance. Too little test data will result in an optimistic and high variance estimation of model performance.
It is critical to make this “common knowledge” concrete with worked examples.
In this post, we will work through a detailed case study for developing a Multilayer Perceptron neural network on a simple two-class classification problem. You
To finish reading, please visit source site