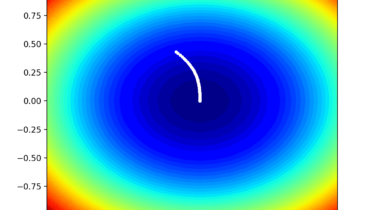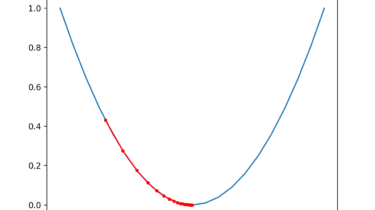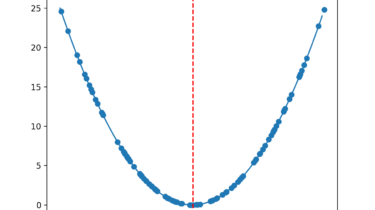
Random Search and Grid Search for Function Optimization
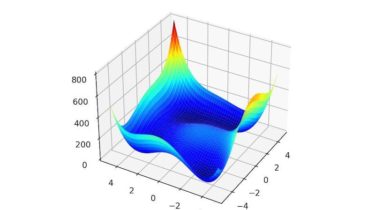
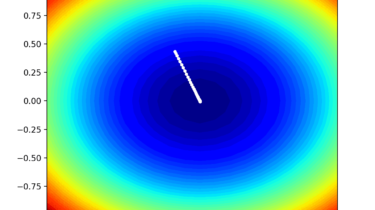
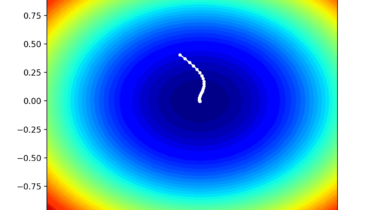
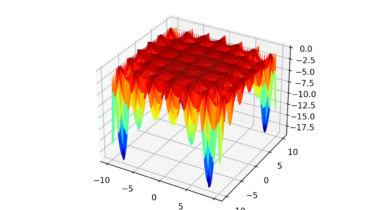
Function optimization requires the selection of an algorithm to efficiently sample the search space and locate a good or best solution. There are many algorithms to choose from, although it is important to establish a baseline for what types of solutions are feasible or possible for a problem. This can be achieved using a naive optimization algorithm, such as a random search or a grid search. The results achieved by a naive optimization algorithm are computationally efficient to generate and […]
Read more