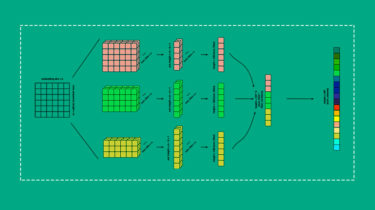
Training BERT Text Classifier on Tensor Processing Unit (TPU)
Training hugging face most famous model on TPU for social media Tunisian Arabizi sentiment analysis. Introduction The Arabic speakers usually express themself in local dialect on social media, so Tunisians use Tunisian Arabizi which consists of Arabic written in form of Latin alphabets. The sentiment analysis relies on cultural knowledge and word sense with contextual information. We will be using both Arabizi dialect and sentimental analysis to solve the problem in this project. The competition is hosted on Zindi which […]
Read more