Step by step guide to extract insights from free text (unstructured data)
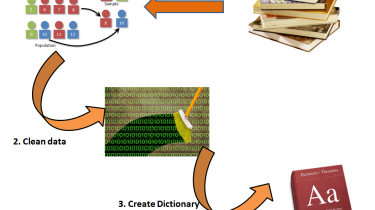
Text Mining is one of the most complex analysis in the industry of analytics. The reason for this is that, while doing text mining, we deal with unstructured data. We do not have clearly defined observation and variables (rows and columns). Hence, for doing any kind of analytics, you need to first convert this unstructured data into a structured dataset and then proceed with normal modelling framework. The additional step of converting an unstructured data into a structured format is […]
Read more