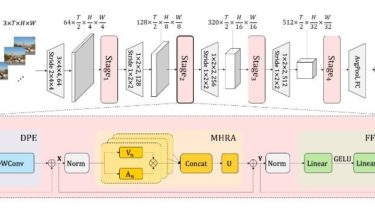
Implementation of Trajectory Transformer with attention caching and batched beam search
This is reimplementation of Trajectory Transformer, introduced in Offline Reinforcement Learningas One Big Sequence Modeling Problem paper. The original implementation has few problems with inference speed, namely quadratic attention duringinference and sequential rollouts. The former slows down planning a lot, while the latter does notallow to do rollouts in parallel and utilize GPU to the full. Still, even after all changes, it is not that fast compared to traditional methods such as PPO or SAC/DDPG.However, the gains are huge, what […]
Read more