official implementation of UniFormer
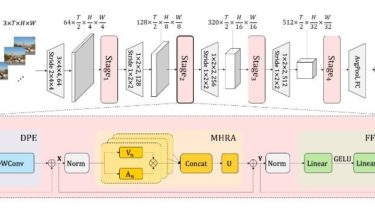
This repo is the official implementation of “Uniformer: Unified Transformer for Efficient Spatiotemporal Representation Learning”. It currently includes code and models for the following tasks:
Updates
01/13/2022
[Initial commits]:
-
Pretrained models on ImageNet-1K, Kinetics-400, Kinetics-600, Something-Something V1&V2
-
The supported code and models for image classification and video classification are provided.
Introduction
UniFormer (Unified transFormer) is introduce in arxiv, which effectively unifies 3D convolution and spatiotemporal self-attention in a concise transformer format. We adopt local MHRA in shallow layers to largely reduce computation burden and global MHRA in deep layers to learn global token relation.
UniFormer achieves strong performance on video classification. With only ImageNet-1K pretraining, our UniFormer achieves 82.9%/84.8% top-1 accuracy on Kinetics-400/Kinetics-600, while requiring 10x fewer GFLOPs