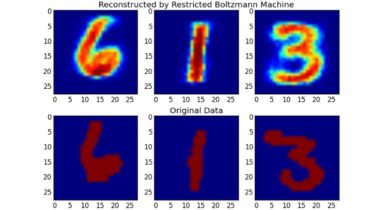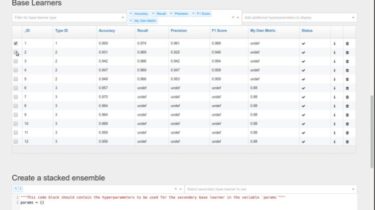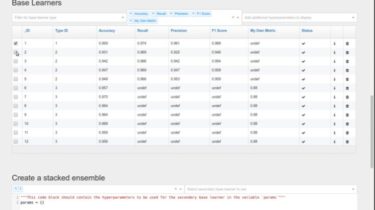
Regularized Greedy Forest: A tree ensemble machine learning method described
Regularized Greedy Forest Regularized Greedy Forest (RGF) is a tree ensemble machine learning method described in this paper. RGF can deliver better results than gradient boosted decision trees (GBDT) on a number of datasets and it has been used to win a few Kaggle competitions. Unlike the traditional boosted decision tree approach, RGF works directly with the underlying forest structure. RGF integrates two ideas: one is to include tree-structured regularization into the learning formulation; and the other is to employ […]
Read more