Image Detector and Convertor App created using python’s Pillow, OpenCV, cvlib, numpy and streamlit packages
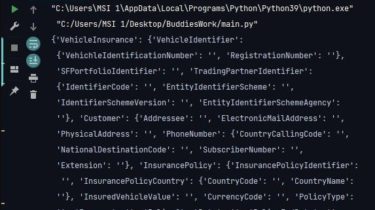
Image Detector and Convertor App Image Detector and Convertor App created using python’s Pillow, OpenCV, cvlib, numpy and streamlit packages. Image Detector can perform Face Detection, Gender Detection and Object Detection using cvlib’s detect_face(), detect_gender() and detect_common_objects() Image Filters can perform Gray Scale Effect, Pencil Drawing Effect, Sepia Effect, Summer Effect, Winter Effect, Invert Effect and also can alter Image’s Contrast, Brightness and Blurrinessusing OpenCV functions. App Interface 👇:-
Read more