Block-wisely Supervised Neural Architecture Search with Knowledge Distillation
This repository provides the code of our paper: Blockwisely Supervised Neural Architecture Search with Knowledge Distillation.
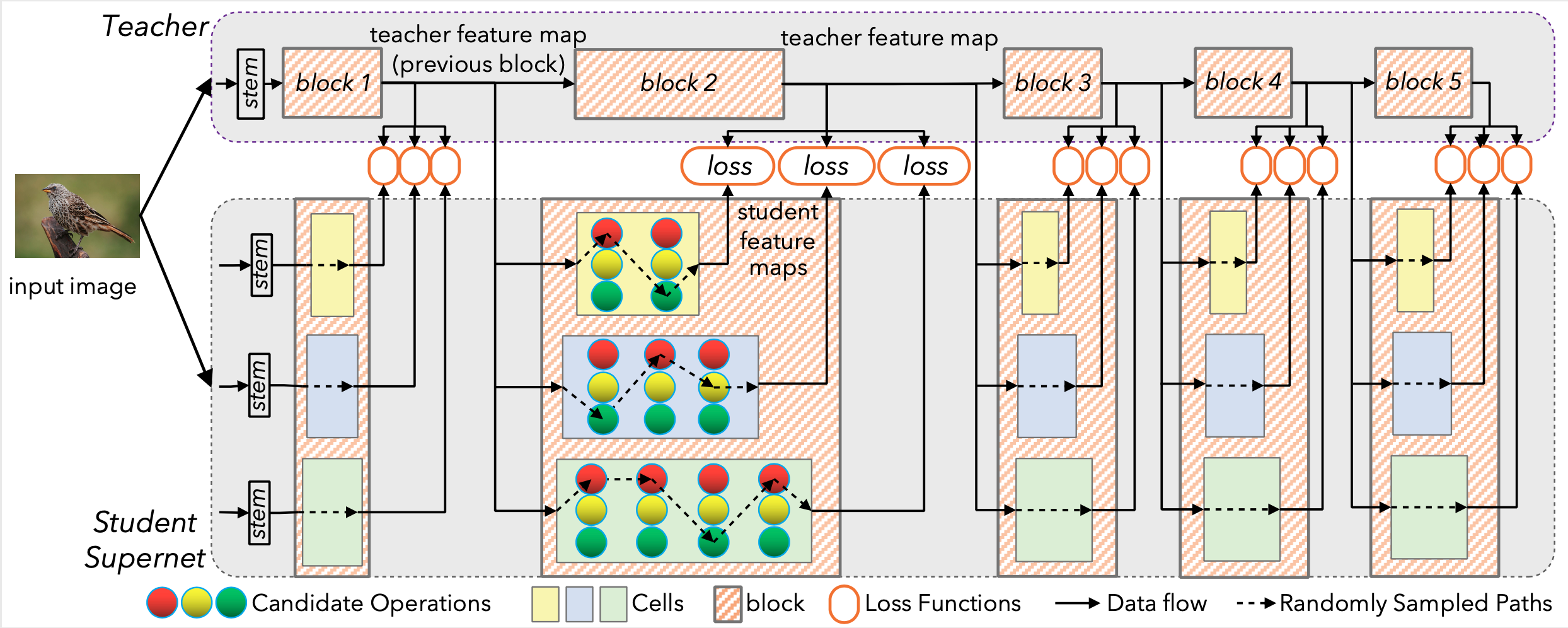
Illustration of DNA. Each cell of the supernet is trained independently to mimic the behavior of the corresponding teacher block.

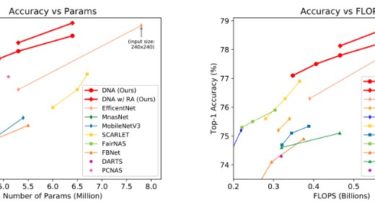
Comparison of model ranking for DNA vs. DARTS, SPOS and MnasNet under two different hyper-parameters.
Our Trained Models

Usage
1. Requirements
- Install PyTorch (pytorch.org)
- Install third-party requirements
- Download the ImageNet dataset and move validation images to labeled subfolders
2. Searching
The code for supernet training, evaluation and searching is under searching directory.
i) Train & evaluate the block-wise supernet with knowledge distillation
- Modify datadir in
initialize/data.yamlto your ImageNet path. - Modify nproc_per_node in
dist_train.shto