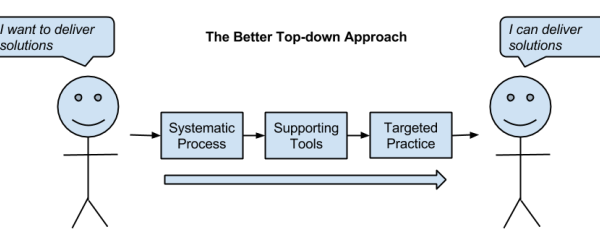
Choosing Machine Learning Algorithms: Lessons from Microsoft Azure
Last Updated on August 12, 2019 Microsoft recently launched support for machine learning in their Azure cloud computing platform. Buried in some of their technical documentation for the platform are some resources that you may find useful for thinking about what machine learning algorithm to use in different situations. In this post we take a look at the Microsoft recommendations for machine learning algorithms and the lessons that we can use when working through machine learning problems on any platform. […]
Read more