Python bindings for Podman’s RESTful API
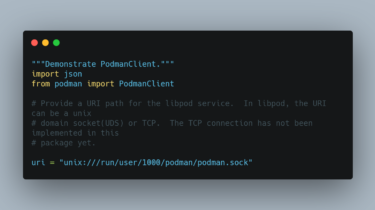
podman-py This python package is a library of bindings to use the RESTful API of Podman. It is currently under development and contributors are welcome! Dependencies Example usage “””Demonstrate PodmanClient.””” import json from podman import PodmanClient # Provide a URI path for the libpod service. In libpod, the URI can be a unix # domain socket(UDS) or TCP. The TCP connection has not been implemented in this # package yet. uri = “unix:///run/user/1000/podman/podman.sock” with PodmanClient(base_url=uri) as client: version = client.version() […]
Read more