A2T: Towards Improving Adversarial Training of NLP Models
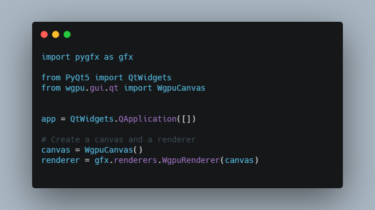
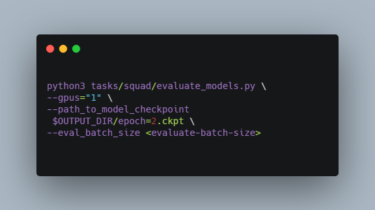
This is the source code for the EMNLP 2021 (Findings) paper “Towards Improving Adversarial Training of NLP Models”. If you use the code, please cite the paper: @misc{yoo2021improving, title={Towards Improving Adversarial Training of NLP Models}, author={Jin Yong Yoo and Yanjun Qi}, year={2021}, eprint={2109.00544}, archivePrefix={arXiv}, primaryClass={cs.CL} } Prerequisites The work heavily relies on the TextAttack package. In fact, the main training code is implemented in the TextAttack package. Required packages are listed in the requirements.txt file. pip install -r requirements.txt […]
Read more