A software toolkit for weak supervision applied to NLP tasks
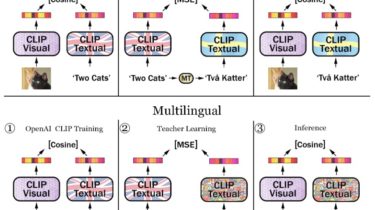
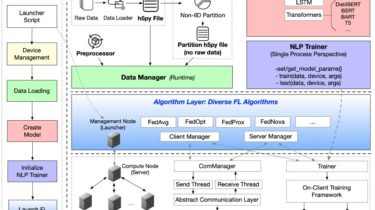
skweak Labelled data remains a scarce resource in many practical NLP scenarios. This is especially the case when working with resource-poor languages (or text domains), or when using task-specific labels without pre-existing datasets. The only available option is often to collect and annotate texts by hand, which is expensive and time-consuming. skweak (pronounced /skwi:k/) is a Python-based software toolkit that provides a concrete solution to this problem using weak supervision. skweak is built around a very simple idea: Instead of […]
Read more