OpenAI CLIP text encoders for any language
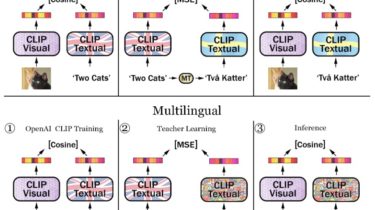
Multilingual-CLIP
OpenAI CLIP text encoders for any language.
OpenAI recently released the paper Learning Transferable Visual Models From Natural Language Supervision in which they present the CLIP (Contrastive Language–Image Pre-training) model. This model is trained to connect text and images, by matching their corresponding vector representations using a contrastive learning objective. CLIP consists of two separate models, a visual encoder and a text encoder. These were trained on a wooping 400 Million images and corresponding captions. OpenAI has since released a set of their smaller CLIP models, which can be found on the official CLIP Github.
We propose a fine-tuning to replace the original English text encoder with a pre-trained text model in any language. This method makes it possible to adapt the powerful CLIP model to any language