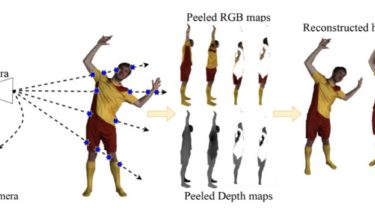
Performance monitoring and testing of OpenStack
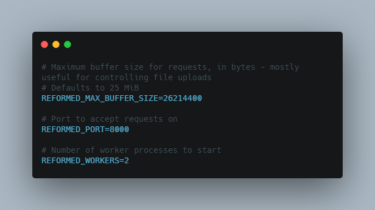
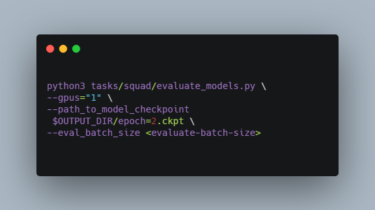
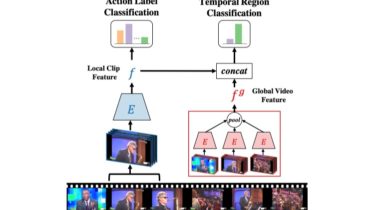
Browbeat Browbeat is a performance tuning and analysis tool for OpenStack. Browbeat is free, Open Source software. Analyze and tune your Cloud for optimal performance. Create Rally workloads for performance and scale testing. Automate deployment of common data analysis tools. Documentation Browbeat documentation is available at https://browbeat.readthedocs.io/ GitHub https://github.com/cloud-bulldozer/browbeat
Read more