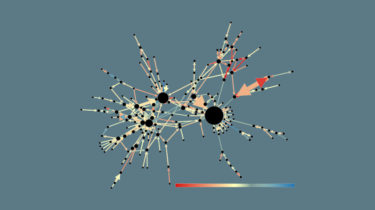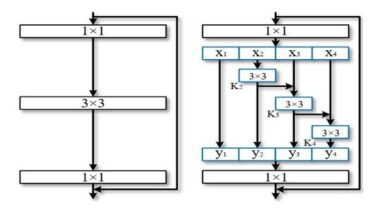
Res2Net: A New Multi-scale Backbone Architecture
Res2Net The official pytorch implemention of the paper “Res2Net: A New Multi-scale Backbone Architecture” Our paper is accepted by IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI). We propose a novel building block for CNNs, namely Res2Net, by constructing hierarchical residual-likeconnections within one single residual block. The Res2Net represents multi-scale features at a granular level and increases the rangeof receptive fields for each network layer. The proposed Res2Net block can be plugged into the state-of-the-art backbone CNN models,e.g. , […]
Read more