Writing high-level code for parallel high-performance stencil computations
ParallelStencil.jl
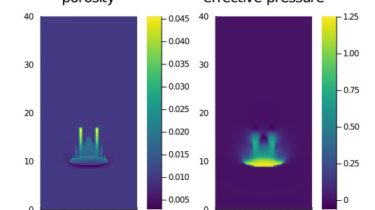
ParallelStencil empowers domain scientists to write architecture-agnostic high-level code for parallel high-performance stencil computations on GPUs and CPUs. Performance similar to CUDA C can be achieved, which is typically a large improvement over the performance reached when using only CUDA.jl Array programming. For example, a 2-D shallow ice solver presented at JuliaCon 2020 [1] achieved a nearly 20 times better performance than a corresponding CUDA.jl Array programming implementation; in absolute terms, it reached 70% of the theoretical upper performance bound of the used Nvidia P100 GPU, as defined by the effective throughput metric, T_eff (note that T_eff is very different from common throughput metrics, see section Performance metric). The GPU performance of the solver is reported in green, the CPU performance in blue:
