Visual Question Answering in Pytorch
/! New version of pytorch for VQA available here: https://github.com/Cadene/block.bootstrap.pytorch
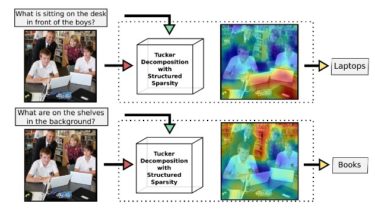
This repo was made by Remi Cadene (LIP6) and Hedi Ben-Younes (LIP6-Heuritech), two PhD Students working on VQA at UPMC-LIP6 and their professors Matthieu Cord (LIP6) and Nicolas Thome (LIP6-CNAM). We developed this code in the frame of a research paper called MUTAN: Multimodal Tucker Fusion for VQA which is (as far as we know) the current state-of-the-art on the VQA 1.0 dataset.
The goal of this repo is two folds:
- to make it easier to reproduce our results,
- to provide an efficient and modular code base to the community for further research on other VQA datasets.
If you have any questions about our code or model, don’t hesitate to contact