Vision Transformer for Fast and Efficient Scene Text Recognition
deep-text-recognition-benchmark
ViTSTR is a simple single-stage model that uses a pre-trained Vision Transformer (ViT) to perform Scene Text Recognition (ViTSTR). It has a comparable accuracy with state-of-the-art STR models although it uses significantly less number of parameters and FLOPS. ViTSTR is also fast due to the parallel computation inherent to ViT architecture.
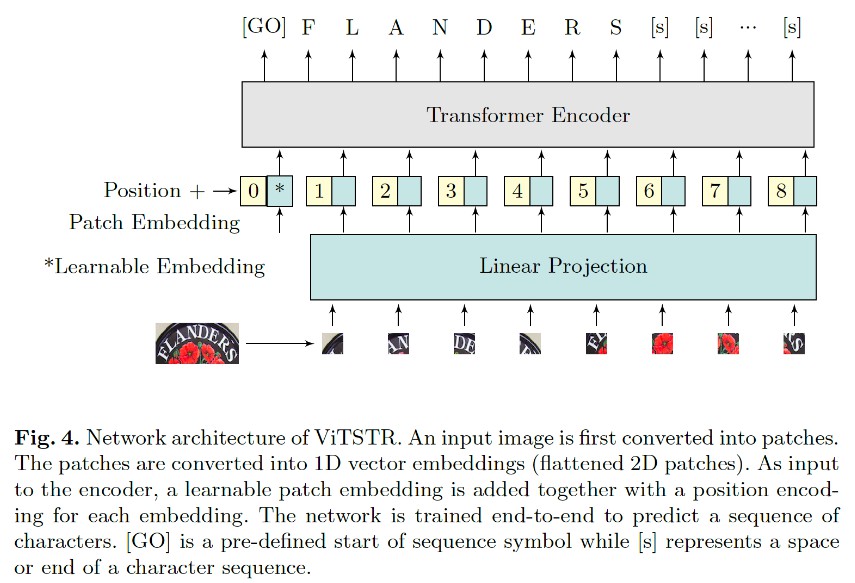
ViTSTR is built using a fork of CLOVA AI Deep Text Recognition Benchmark whose original documentation is at the bottom. Below we document how to train and evaluate ViTSTR-Tiny and ViTSTR-small.
Install requirements
pip3 install -r requirements.txt
Dataset
Download lmdb dataset. See CLOVA AI original documentation below.
Quick validation using a pre-trained model
ViTSTR-Small
CUDA_VISIBLE_DEVICES=0 python3 test.py --eval_data data_lmdb_release/evaluation
--benchmark_all_eval --Transformation None --FeatureExtraction None
--SequenceModeling None --Prediction None --Transformer
--sensitive