A Gentle Introduction to Expectation-Maximization (EM Algorithm)
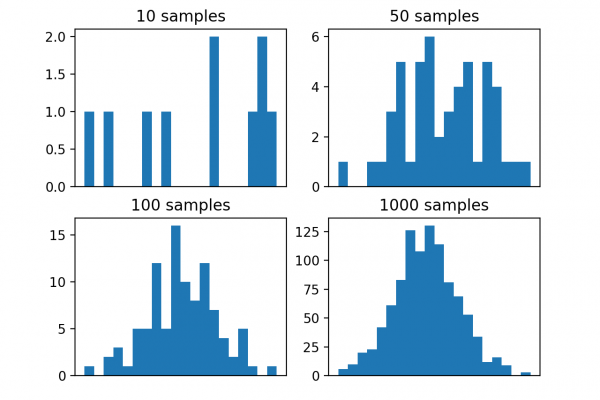
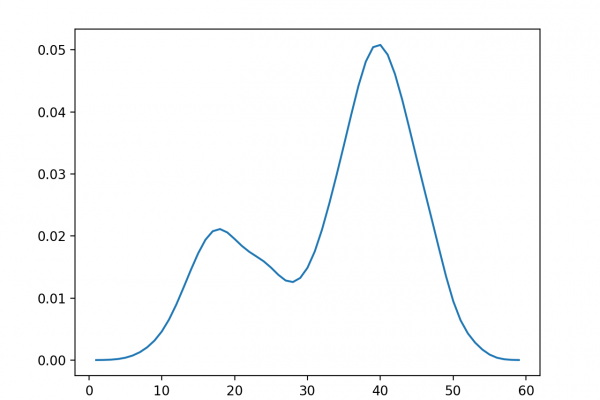
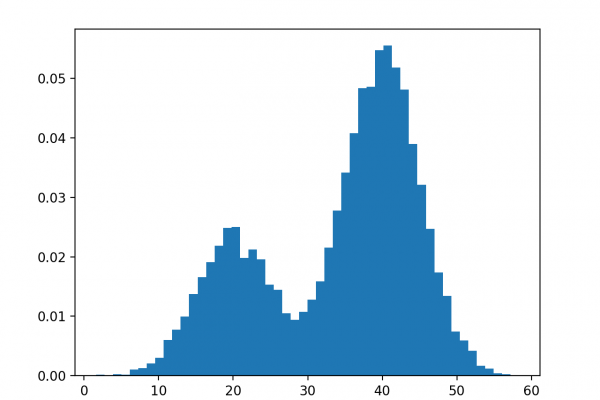
Last Updated on August 28, 2020 Maximum likelihood estimation is an approach to density estimation for a dataset by searching across probability distributions and their parameters. It is a general and effective approach that underlies many machine learning algorithms, although it requires that the training dataset is complete, e.g. all relevant interacting random variables are present. Maximum likelihood becomes intractable if there are variables that interact with those in the dataset but were hidden or not observed, so-called latent variables. […]
Read more