Source-filter based Decomposed Modeling for Speech Synthesis
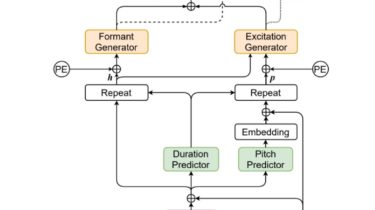
FastPitchFormant – PyTorch Implementation
PyTorch Implementation of FastPitchFormant: Source-filter based Decomposed Modeling for Speech Synthesis.
Dependencies
You can install the Python dependencies with
pip3 install -r requirements.txt
Inference
You have to download the pretrained models and put them in output/ckpt/LJSpeech/.
For English single-speaker TTS, run
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step 1000000 --mode single -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
The generated utterances will be put in output/result/.
Batch Inference
Batch inference is also supported, try
python3 synthesize.py --source preprocessed_data/LJSpeech/val.txt --restore_step 1000000 --mode batch -p config/LJSpeech/preprocess.yaml -m config/LJSpeech/model.yaml -t config/LJSpeech/train.yaml
to synthesize all utterances in preprocessed_data/LJSpeech/val.txt
Controllability
The pitch/speaking rate of the synthesized utterances can be controlled by specifying the desired pitch/energy/duration ratios. For example, one can increase the speaking rate by