Saliency-based Span Mixup for Text Classification
SSMix
Saliency-based Span Mixup for Text Classification (Findings of ACL 2021)
Abstract
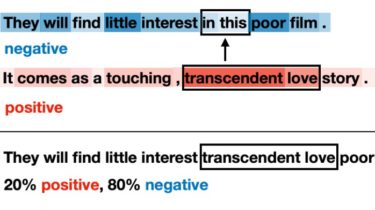
Data augmentation with mixup has shown to be effective on various computer vision tasks. Despite its great success, there has been a hurdle to apply mixup to NLP tasks since text consists of discrete tokens with variable length. In this work, we propose SSMix, a novel mixup method where the operation is performed on input text rather than on hidden vectors like previous approaches. SSMix synthesizes a sentence while preserving the locality of two original texts by span-based mixing and keeping more tokens related to the prediction relying on saliency information. With extensive experiments, we empirically validate that our method outperforms hidden-level mixup methods on the wide range of text classification benchmarks, including textual entailment, sentiment