PromptDet: Expand Your Detector Vocabulary with Uncurated Images
Introduction
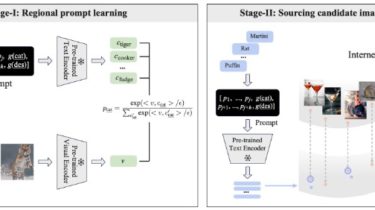
The goal of this work is to establish a scalable pipeline for expanding an object detector towards novel/unseen categories, using zero manual annotations. To achieve that, we make the following four contributions: (i) in pursuit of generalisation, we propose a two-stage open-vocabulary object detector that categorises each box proposal by a classifier generated from the text encoder of a pre-trained visual-language model; (ii) To pair the visual latent space (from RPN box proposal) with that of the pre-trained text encoder, we propose the idea of regional prompt learning to optimise a couple of learnable prompt vectors, converting the textual embedding space to fit those visually object-centric images; (iii) To scale up the learning procedure towards detecting a wider spectrum of objects, we