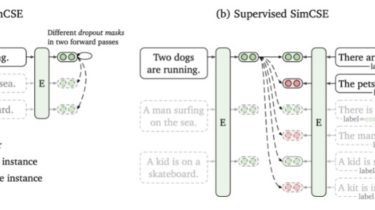
Simple Contrastive Learning of Sentence Embeddings
SimCSE We propose a simple contrastive learning framework that works with both unlabeled and labeled data. Unsupervised SimCSE simply takes an input sentence and predicts itself in a contrastive learning framework, with only standard dropout used as noise. Our supervised SimCSE incorporates annotated pairs from NLI datasets into contrastive learning by using entailment pairs as positives and contradiction pairs as hard negatives. The following figure is an illustration of our models. Use our models out of the box Our pre-trained […]
Read more