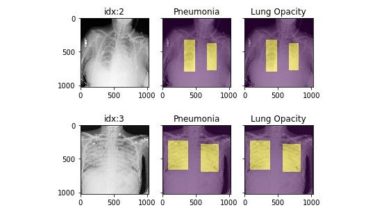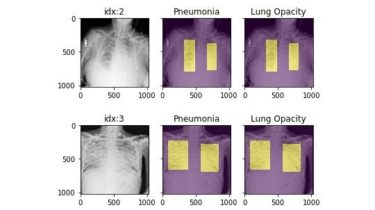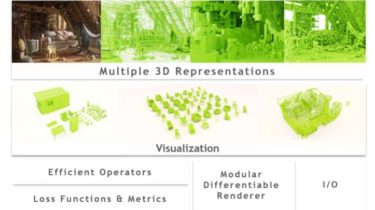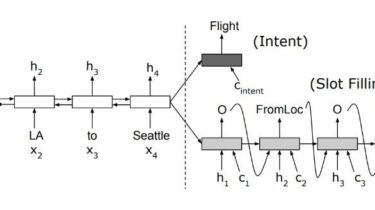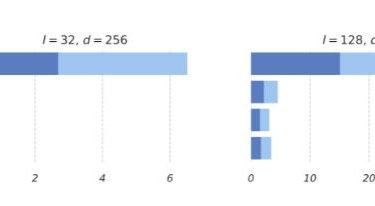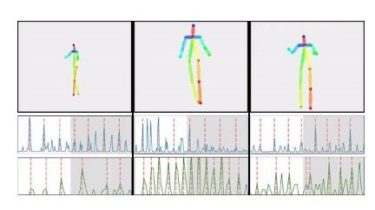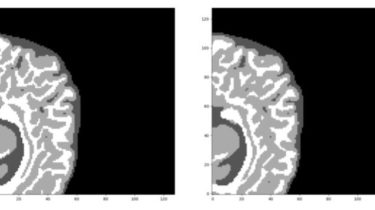
A pytorch-based deep learning framework for multi-modal 2D/3D medical image segmentation
We strongly believe in open and reproducible deep learning research. Our goal is to implement an open-source medical image segmentation library of state of the art 3D deep neural networks in PyTorch. We also implemented a bunch of data loaders of the most common medical image datasets. This project started as an MSc Thesis and is currently under further development. Although this work was initially focused on 3D multi-modal brain MRI segmentation we are slowly adding
Read more