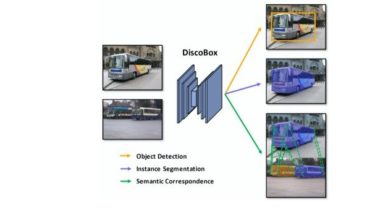
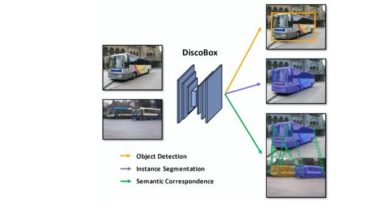
The Official PyTorch Implementation of DiscoBox
DiscoBox: Weakly Supervised Instance Segmentation and Semantic Correspondence from Box Supervision Paper | Project page | Demo (Youtube) | Demo (Bilibili) DiscoBox: Weakly Supervised Instance Segmentation and Semantic Correspondence from Box Supervision.Shiyi Lan, Zhiding Yu, Chris Choy, Subhashree Radhakrishnan, Guilin Liu, Yuke Zhu, Larry Davis, Anima AnandkumarInternational Conference on Computer Vision (ICCV) 2021 This repository contains the official Pytorch implementation of training & evaluation code and pretrained models for DiscoBox.DiscoBox is a
Read more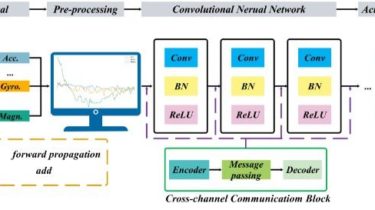
Shallow Convolutional Neural Networks for Human Activity Recognition using Wearable Sensors
[IEEE TIM 2021-1] Shallow Convolutional Neural Networks for Human Activity Recognition using Wearable SensorsAll of datasets we use in this paper can be download from Internet and you can find we how to process data in this paper.This is my first time to open source, so there maybe some problems in my codes and I will improve this project in the near feature.Thanks! Requirements ● Python3● PyTorch (My version 1.9.0+cu111, please choose compatibility with your computer)● Scikit-learn● Numpy How to […]
Read more
A small tool that is there to send messages with beta webhooks
📎 Webhook-discord Le but de se tool c’est que tu peux envoier vos webhook discord sur vos serveur et les customiser Pour lancer le projet il faut avoir python installer sur votre machine puis ensuite télécharger le projet et glisser le dossier du projet sur votre Ide de votre choix et puis installer le module : pip install discord_webhook Ensuite lancer le projet. 👤 Auteur GitHub View Github
Read more
Annotate your Python requirements.txt file with summaries of each package
Annotate your Python requirements.txt file with a short summary of each package. This tool: takes a Python requirements.txt file as input fetches the summary of each package from the PyPi registry outputs an equivalent requirements list with added comments summarizing each package It can be used as a Python module or a command line script. Example Before: black==21.9b0 gunicorn==20.1.0 pytz==2021.3 requests==2.26.0 rope==0.20.1 whitenoise==5.3.0 After:
Read more
Machine Learning with 5 different algorithms
In this project, the dataset was created through a survey opened on Google forms.The purpose of the form is to find the person’s favorite shopping type based on the information provided. In this context, 13 questions were asked to the user.As a result of these questions, the estimation of the shopping type, which is a classification problem, will be carried out with 5 different algorithms. These algorithms; Logistic Regression Random Forest Classifier Support Vector Machine K Neighbors Decision Tree algorithms […]
Read more
Persian Kaldi profile for Rhasspy built from open speech data
A Rhasspy profile for Persian (fa). Installation Get started by first installing Vosk: # Create virtual environment python3 -m venv .venv source .venv/bin/activate pip3 install –upgrade pip pip3 install –upgrade wheel setuptools # Install Vosk pip3 install vosk Next, download the model and extract it: wget ‘https://github.com/rhasspy/fa_kaldi-rhasspy/releases/download/v1.0/vosk-model-small-fa-rhasspy-0.15.zip’ unzip vosk-model-small-fa-rhasspy-0.15.zip Finally, run the transcribe.py Python program with the model and an audio file:
Read more
A cool, modern and responsive django admin application based on bootstrap 5
A cool, modern and responsive django admin application based on bootstrap 5 Documentation: readthedocs Live Demo Now you can try django-baton using the new shining live demo! Login with user demo and password demo https://django-baton-demo.herokuapp.com/ Features Supports Django >= 2.1. For older versions of Django, please use [email protected] This application was written with one concept in mind: overwrite as few django templates as possible. Everything is styled through CSS and when required, JS is used. Based on Bootstrap 5 and […]
Read more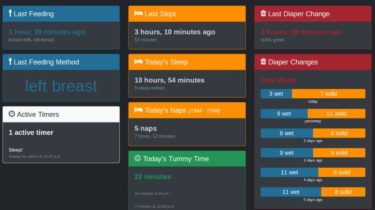
A buddy to help caregivers track sleep, feedings, diaper changes, and tummy time to learn about and predict baby’s needs
A buddy for babies! Helps caregivers track sleep, feedings, diaper changes, tummy time and more to learn about and predict baby’s needs without (as much) guess work. Demo A demo of Baby Buddy is available on Heroku. The demo instance resets every hour. Login credentials are: Username: admin Password: admin Deployment The default user name and password for Baby Buddy is admin/admin. For any deployment, log in and change the default admin password immediately. Many of Baby Buddy’s configuration settings […]
Read moreMachine Translation Weekly 89: BPE and Memorization
Similar to last week, I will discuss a paper about input segmentation. The paper is not directly about machine translation or multilinguality but brings interesting insights for Transformer models in general. The title of the paper is How BPE affects memorization in Transformers, it has authors from Facebook AI and the preprint appeared on Thursday on arXiv. The paper presents a series of experiments with Transformer models for natural language inferences and different sizes of BPE-based vocabulary by which they […]
Read more