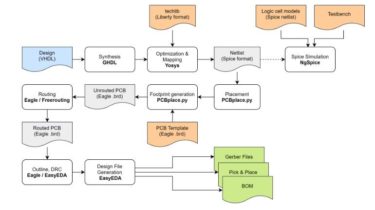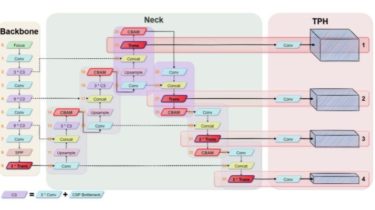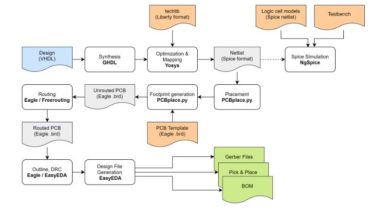
Maintained wavelink fork for pycord
Wavelink is robust and powerful Lavalink wrapper for Pycord!Wavelink features a fully asynchronous API that’s intuitive and easy to use. Support For support using Pycord.WaveLink, please join the official support server on Discord. Installation The following commands are currently the valid ways of installing WaveLink. WaveLink requires Python 3.8+ Windows py -3.9 -m pip install pycord.wavelink –pre Linux python3.9 -m pip install pycord.wavelink –pre Getting Started
Read more