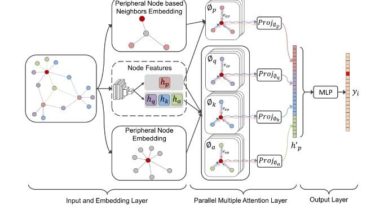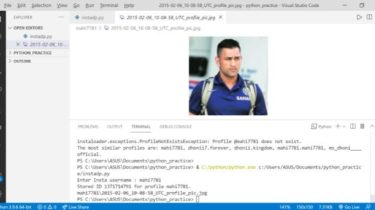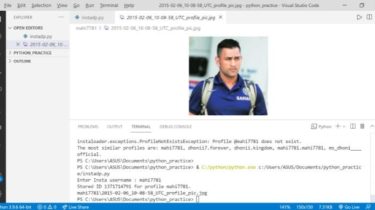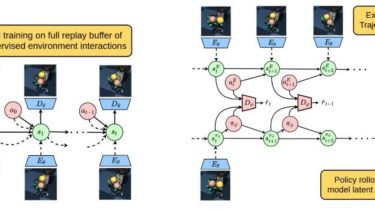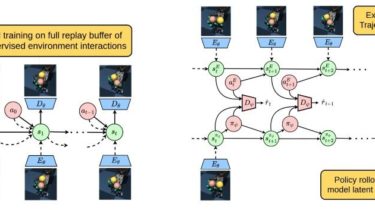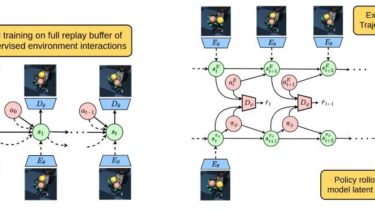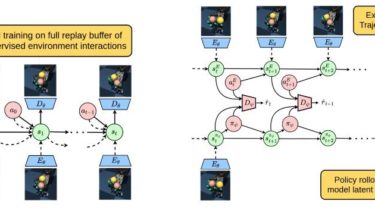
Cli tool to browse and play anime
browse and watch anime (scrape from gogoanime) (wip) basically ani-cli but in python cuz python good demo dependencies installation pip install git+https://github.com/sleepntsheep/ani-cli usages or notes it take quite long to open mpv, i don’t know why too 💀 GitHub View Github
Read more