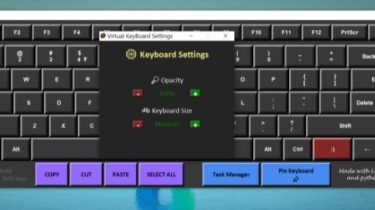
A Virtual Keyboard GUI app made in python using tkinter
A GUI application made in python using tkinter This is my first ever proper GUI based application project after learning tkinter recently. I made it to practice and get more used to working with tkinter Features You can open the keyboard settings menu with the button in the bottom right corner The keyboard is stored as a class named VirtualKeyboard, which you can import and use VirtualKeyboard().start() to use the virtual keyboard The keyboard comes in 5 sizes: Very Small […]
Read more