Reproducible experiments with 3D printers
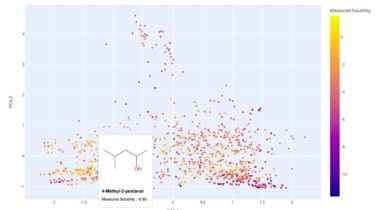
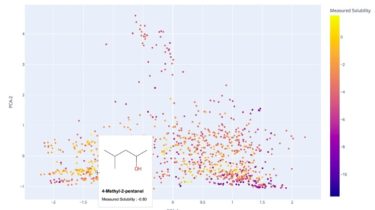
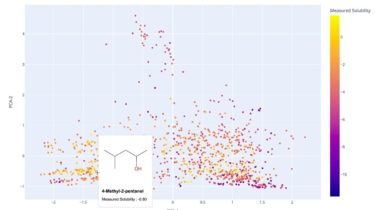
Make it better, with data. And confidence. This repo is a collection of scripts and notes for running reproducible experiments with printers. You can run a single gcode action a whole bunch of times, conveniently, and record console outputs of interest from it. You can run one of multiple pre-defined tests, or add your own in Python. You can compare the before-and-after results from a test, with statistical confidence, to see if what you did… did anything at all. Conveniently, […]
Read more