Location-Sensitive Visual Recognition with Cross-IOU Loss
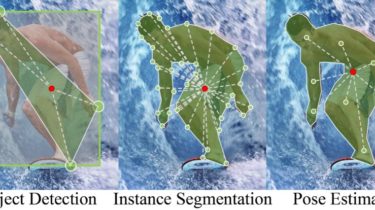
LSNet
The location-sensitive visual recognition tasks, including object detection, instance segmentation, and human pose estimation, can be formulated into localizing an anchor point (in red) and a set of landmarks (in green). Our work aims to offer a unified framework for these tasks.
Abstract
Object detection, instance segmentation, and pose estimation are popular visual recognition tasks which require localizing the object by internal or boundary landmarks. This paper summarizes these tasks as location-sensitive visual recognition and proposes a unified solution named location-sensitive network (LSNet). Based on a deep neural network as the backbone, LSNet predicts an anchor point and a set of landmarks which together define the shape of the target object. The key to optimizing the LSNet lies in the ability of fitting various scales, for which