Imbalanced Multiclass Classification with the Glass Identification Dataset
Last Updated on August 21, 2020
Multiclass classification problems are those where a label must be predicted, but there are more than two labels that may be predicted.
These are challenging predictive modeling problems because a sufficiently representative number of examples of each class is required for a model to learn the problem. It is made challenging when the number of examples in each class is imbalanced, or skewed toward one or a few of the classes with very few examples of other classes.
Problems of this type are referred to as imbalanced multiclass classification problems and they require both the careful design of an evaluation metric and test harness and choice of machine learning models. The glass identification dataset is a standard dataset for exploring the challenge of imbalanced multiclass classification.
In this tutorial, you will discover how to develop and evaluate a model for the imbalanced multiclass glass identification dataset.
After completing this tutorial, you will know:
- How to load and explore the dataset and generate ideas for data preparation and model selection.
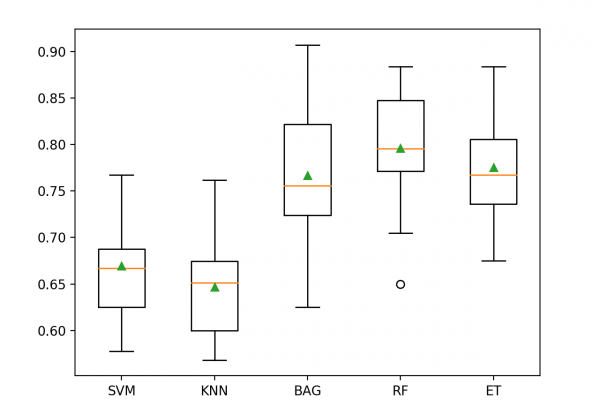
- How to systematically evaluate a suite of machine learning models with a robust test harness.
- How to fit a final model and use
To finish reading, please visit source site