How to Use Greedy Layer-Wise Pretraining in Deep Learning Neural Networks
Last Updated on August 25, 2020
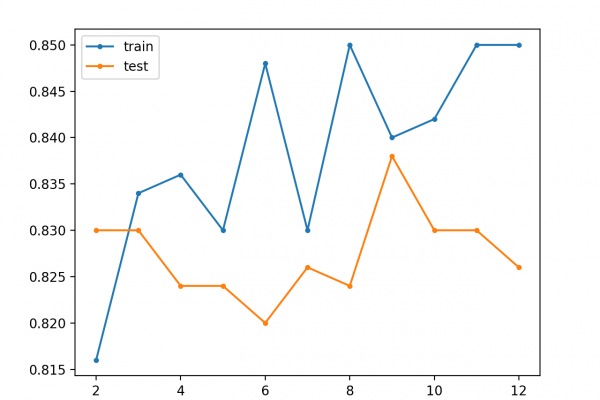
Training deep neural networks was traditionally challenging as the vanishing gradient meant that weights in layers close to the input layer were not updated in response to errors calculated on the training dataset.
An innovation and important milestone in the field of deep learning was greedy layer-wise pretraining that allowed very deep neural networks to be successfully trained, achieving then state-of-the-art performance.
In this tutorial, you will discover greedy layer-wise pretraining as a technique for developing deep multi-layered neural network models.
After completing this tutorial, you will know:
- Greedy layer-wise pretraining provides a way to develop deep multi-layered neural networks whilst only ever training shallow networks.
- Pretraining can be used to iteratively deepen a supervised model or an unsupervised model that can be repurposed as a supervised model.
- Pretraining may be useful for problems with small amounts labeled data and large amounts of unlabeled data.
Kick-start your project with my new book Better Deep Learning, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
- Updated Sep/2019: Fixed plot to transform keys into list (thanks Markus)
- Updated Oct/2019: Updated for Keras 2.3 and TensorFlow 2.0.
- Update
To finish reading, please visit source site