How to Choose a Feature Selection Method For Machine Learning
Last Updated on August 20, 2020
Feature selection is the process of reducing the number of input variables when developing a predictive model.
It is desirable to reduce the number of input variables to both reduce the computational cost of modeling and, in some cases, to improve the performance of the model.
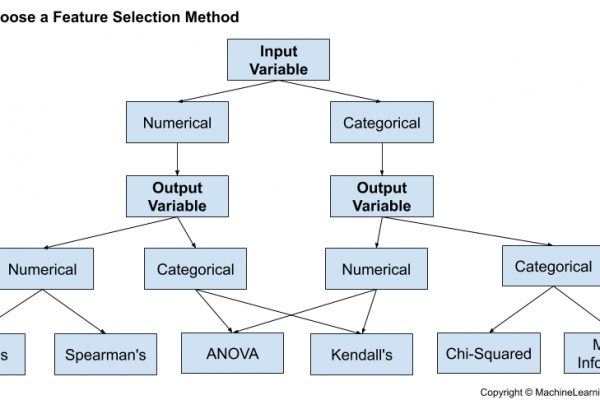
Statistical-based feature selection methods involve evaluating the relationship between each input variable and the target variable using statistics and selecting those input variables that have the strongest relationship with the target variable. These methods can be fast and effective, although the choice of statistical measures depends on the data type of both the input and output variables.
As such, it can be challenging for a machine learning practitioner to select an appropriate statistical measure for a dataset when performing filter-based feature selection.
In this post, you will discover how to choose statistical measures for filter-based feature selection with numerical and categorical data.
After reading this post, you will know:
- There are two main types of feature selection techniques: supervised and unsupervised, and supervised methods may be divided into wrapper, filter and intrinsic.
- Filter-based feature selection methods use statistical measures to score the correlation or dependence between
To finish reading, please visit source site