Text Mining hack: Subject Extraction made easy using Google API
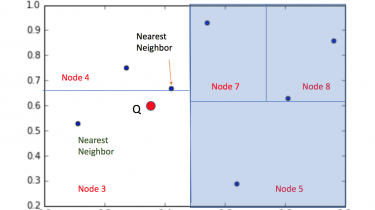
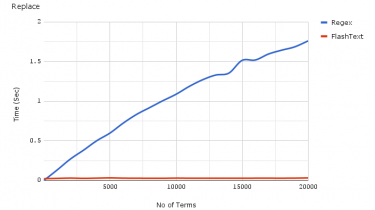
Let’s do a simple exercise. You need to identify the subject and the sentiment in following sentences: Google is the best resource for any kind of information. I came across a fabulous knowledge portal – Analytics Vidhya Messi played well but Argentina still lost the match Opera is not the best browser Yes, like UAE will win the Cricket World Cup. Was this exercise simple? Even if this looks like a simple exercise, now imagine creating an algorithm to do this? How does that […]
Read more