Reduce PDF size without sacrificing visual quality or metadata
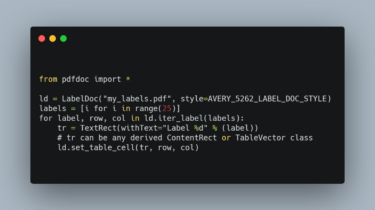
DietPDF aims at reducing PDF file size while not degrading quality nor losingmetadata. Description DietPDF aims at reducing PDF file size while not degrading quality. Here are some tricks used to achieve this goal: Use Zopfli instead of Zlib to get better compression ratio while beingcompatible with Zlib. Use JpegTran to optimize and remove unnecessary data from embedded JPEGs. Use of Run-Length Encoding to help Zopfli achieve better compression. Use Zopfli on embedded JPEGs, it helps sometimes Remove unnecessary spaces […]
Read more