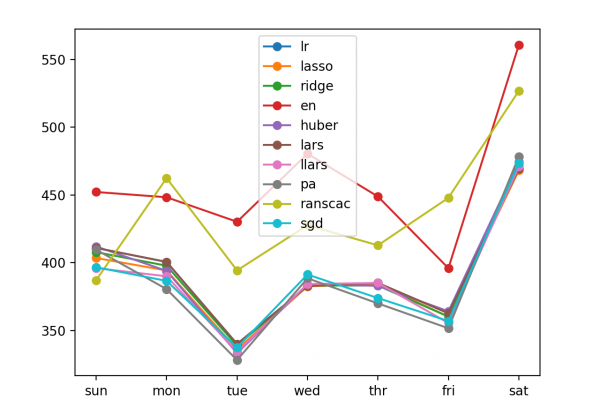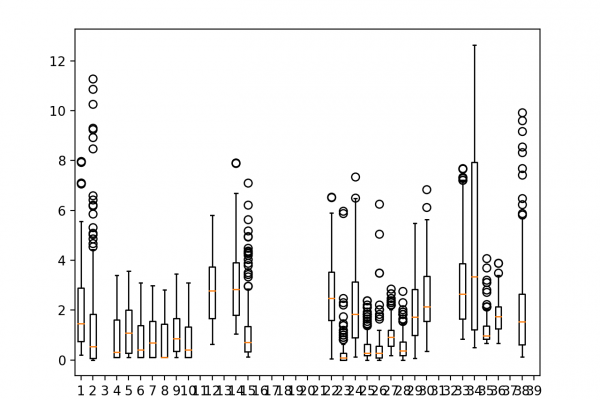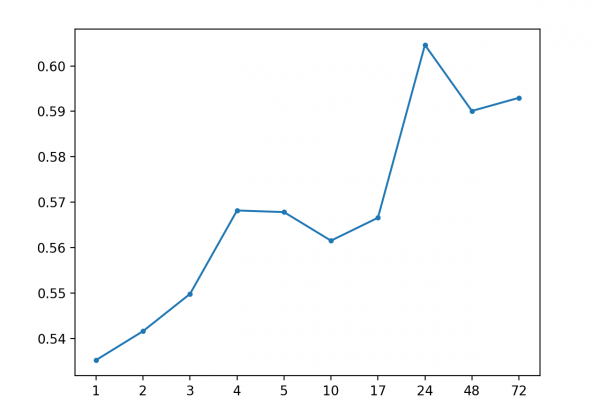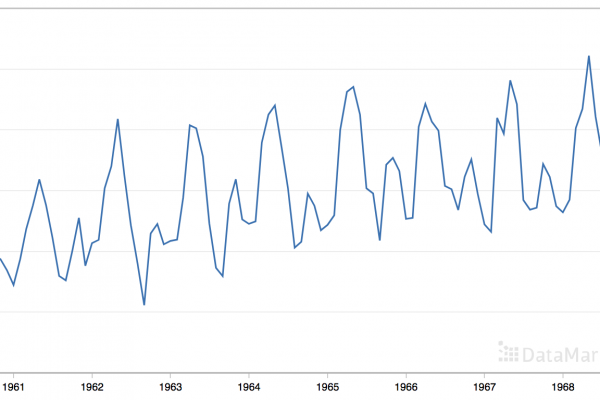
Autoregression Forecast Model for Household Electricity Consumption
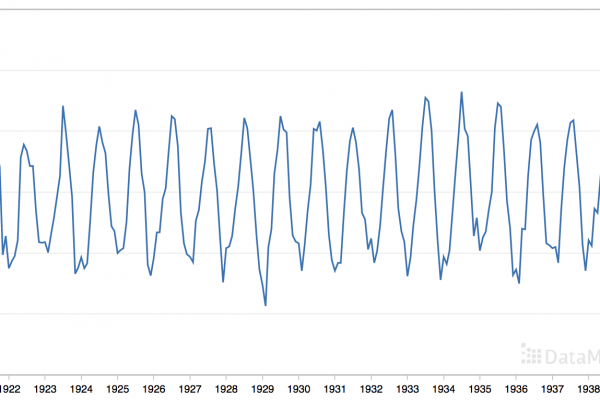
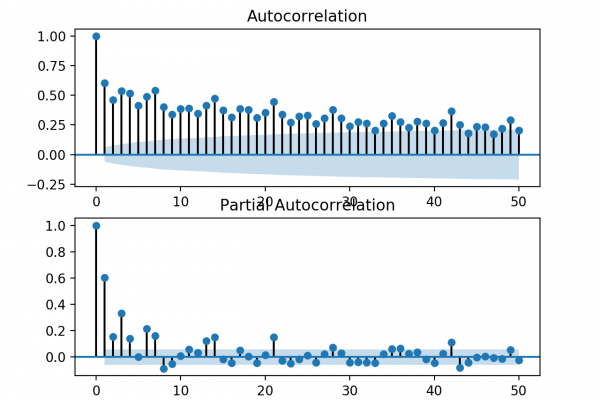
Last Updated on August 28, 2020 Given the rise of smart electricity meters and the wide adoption of electricity generation technology like solar panels, there is a wealth of electricity usage data available. This data represents a multivariate time series of power-related variables that in turn could be used to model and even forecast future electricity consumption. Autocorrelation models are very simple and can provide a fast and effective way to make skillful one-step and multi-step forecasts for electricity consumption. […]
Read more