Category: Language Models
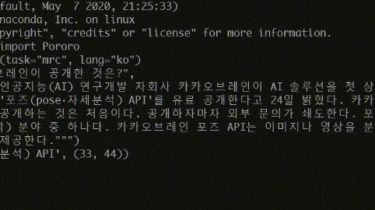
PORORO: Platform Of neuRal mOdels for natuRal language prOcessing
pororo performs Natural Language Processing and Speech-related tasks. It is easy to solve various subtasks in the natural language and speech processing field by simply passing the task name. Installation Or you can install it locally: git clone https://github.com/kakaobrain/pororo.git cd pororo pip install -e . For library installation for specific tasks other than the common modules, please refer to INSTALL.md For the utilization of Automatic Speech Recognition,
Read more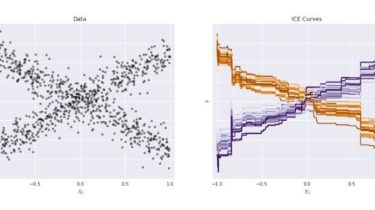
Interpretability and explainability of data and machine learning models
The AI Explainability 360 toolkit is an open-source library that supports interpretability and explainability of datasets and machine learning models. The AI Explainability 360 Python package includes a comprehensive set of algorithms that cover different dimensions of explanations along with proxy explainability metrics. The AI Explainability 360 interactive experience provides a gentle introduction to the concepts and capabilities by walking through an example use case for different consumer personas. The tutorials and example notebooks offer a deeper, data scientist-oriented introduction. […]
Read more
Frustratingly Simple Pretraining Alternatives to Masked Language Modeling
This is the official implementation for “Frustratingly Simple Pretraining Alternatives to Masked Language Modeling” (EMNLP 2021). Requirements torch transformers datasets scikit-learn tensorflow spacy How to pre-train 1. Clone this repository git clone https://github.com/gucci-j/light-transformer-emnlp2021.git 2. Install required packages cd ./light-transformer-emnlp2021 pip install -r requirements.txt requirements.txt is located just under light-transformer-emnlp2021. We also need spaCy’s en_core_web_sm for preprocessing. If you have not installed this model, please run python -m spacy download en_core_web_sm. 3. Preprocess datasets cd ./src/utils python preprocess_roberta.py –path=/path/to/save/data/ You need […]
Read more
A python tools for fine-tuning language models for a task
DataTuner You have just found the DataTuner. This repository provides tools for fine-tuning language models for a task. Installation Environment Creation Assuming you have an existing conda setup, you can setup the environment with the following script. In order to activate the conda environment within the bash script, you need the location of the conda.sh file: bash setup.sh ~/miniconda3/etc/profile.d/conda.sh You can update your existing environment: conda env update -f=environment.yml To start development, activate your environment: conda activate finetune Alternatively, you […]
Read more
Pretrained model on Marathi language using a masked language modeling objective
RoBERTa base model for Marathi Language (मराठी भाषा) Pretrained model on Marathi language using a masked language modeling (MLM) objective. RoBERTa was introduced inthis paper and first released inthis repository. We trained RoBERTa model for Marathi Language during community week hosted by Huggingface 🤗 using JAX/Flax for NLP & CV jax. RoBERTa base model for Marathi language (मराठी भाषा) Model description Marathi RoBERTa is a transformers model pretrained on a large corpus of Marathi data in a self-supervised fashion. Intended […]
Read more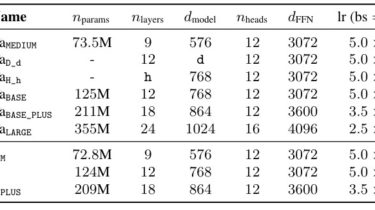
Knowledge Inheritance for Pre-trained Language Models
Knowledge-Inheritance Source code paper: Knowledge Inheritance for Pre-trained Language Models (preprint). The trained model parameters (in Fairseq format) can be downloaded from Tsinghua Cloud. You can use convert_fairseq_to_huggingface.py to convert the Fairseq format into Huggingface’s transformers format easily. We refer the downstream performance evaluation to the implementation of Fairseq (GLUE tasks) and Don’t Stop Pre-training (ACL-ARC / CHEMPROT). If you have any question, feel free to contact us ([email protected]). 1. Available Pretrained Models WB domain: Wikipedia + BookCorpus; CS domain: […]
Read more