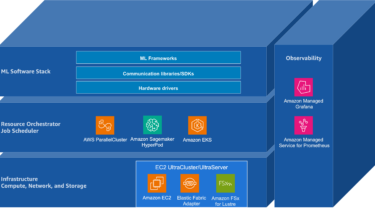
Building Blocks for Foundation Model Training and Inference on AWS
For a long time, “scaling” in foundation models mostly meant one thing: spend more compute on pre-training and capabilities rise. That intuition was supported by empirical work such as Kaplan et al. (2020), which reported predictable power-law trends in loss as you scale model parameters, dataset size, and training compute. In practice, these trends justified sustained investment in large-scale accelerator capacity and the surrounding distributed infrastructure needed to keep it efficiently utilized. But the frontier has evolved—and scaling is no […]
Read more







