Shipping a Trillion Parameters With a Hub Bucket: Delta Weight Sync in TRL
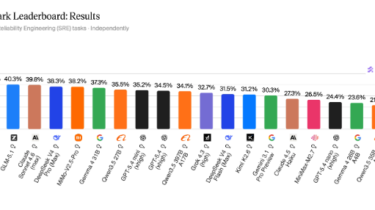
TL;DR, because you have models to train and we respect that: Async RL has a dirty secret: every step, the trainer has to ship the whole model to the inference engine. For a 7B in bf16 that is 14 GB. For a frontier 1T model checkpoint that is on the order of a terabyte. Per step. It turns out you do not have to. Between two consecutive RL optimizer steps, roughly 99% of bf16 weights are bit-identical (and never less […]
Read more