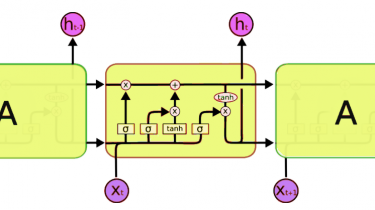
Essentials of Deep Learning : Introduction to Long Short Term Memory
Introduction Sequence prediction problems have been around for a long time. They are considered as one of the hardest problems to solve in the data science industry. These include a wide range of problems; from predicting sales to finding patterns in stock markets’ data, from understanding movie plots to recognizing your way of speech, from language translations to predicting your next word on your iPhone’s keyboard. With the recent breakthroughs that have been happening in data science, it is found […]
Read more







