A Pytree Module system for Deep Learning in JAX
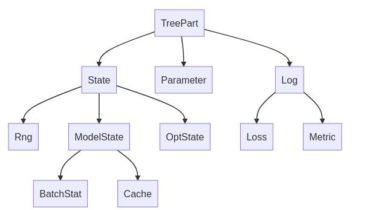
A Pytree-based Module system for Deep Learning in JAX Intuitive: Modules are simple Python objects that respect Object-Oriented semantics and should make PyTorch users feel at home, with no need for separate dictionary structures or complex apply methods. Pytree-based: Modules are registered as JAX PyTrees, enabling their use with any JAX function. No need for specialized versions of jit, grad, vmap, etc. Expressive: In Treex you use type annotations to define what the different parts of your module represent (submodules, […]
Read more