DeepLab resnet v2 model implementation in pytorch
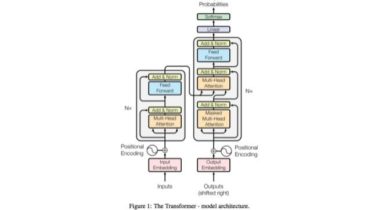
DeepLab resnet v2 model implementation in pytorch. The architecture of deepLab-ResNet has been replicated exactly as it is from the caffe implementation. This architecture calculates losses on input images over multiple scales ( 1x, 0.75x, 0.5x ). Losses are calculated individually over these 3 scales. In addition to these 3 losses, one more loss is calculated after merging the output score maps on the 3 scales. These 4 losses are added to calculate the total loss. Updates 18 July 2017 […]
Read more