A ROS2 port of the linorobot package
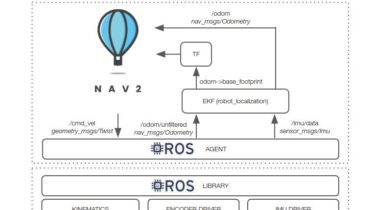
linorobot2 linorobot2 is a ROS2 port of the linorobot package. If you’re planning to build your own custom ROS2 robot (2WD, 4WD, Mecanum Drive) using accessible parts, then this package is for you. This repository contains launch files to easily integrate your DIY robot with Nav2 and a simulation pipeline to run and verify your experiments on a virtual robot in Gazebo. Once the robot’s URDF has been configured in linorobot2_description package, users can easily switch between booting up the […]
Read more