Attention in Long Short-Term Memory Recurrent Neural Networks
Last Updated on August 14, 2019
The Encoder-Decoder architecture is popular because it has demonstrated state-of-the-art results across a range of domains.
A limitation of the architecture is that it encodes the input sequence to a fixed length internal representation. This imposes limits on the length of input sequences that can be reasonably learned and results in worse performance for very long input sequences.
In this post, you will discover the attention mechanism for recurrent neural networks that seeks to overcome this limitation.
After reading this post, you will know:
- The limitation of the encode-decoder architecture and the fixed-length internal representation.
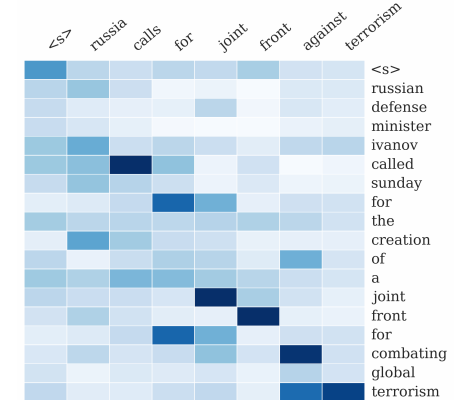
- The attention mechanism to overcome the limitation that allows the network to learn where to pay attention in the input sequence for each item in the output sequence.
- 5 applications of the attention mechanism with recurrent neural networks in domains such as text translation, speech recognition, and more.
Kick-start your project with my new book Long Short-Term Memory Networks With Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
 To finish reading, please visit source site
To finish reading, please visit source site