An audio track separator in tensorflow that successfully separates Vocals and Drums from an input audio song track
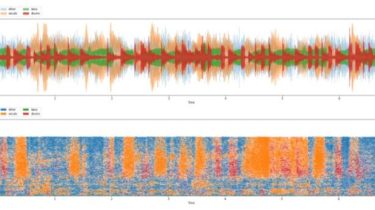

Audio Source Separation is the process of separating a mixture (e.g. a pop band recording) into isolated sounds from individual sources (e.g. just the lead vocals). Basically, splitting a song into separate vocals and instruments.
In this Repository, We developed an audio track separator in tensorflow that successfully separates Vocals and Drums from an input audio song track.
We trained a U-Net model with two output layers. One output layer predicts the Vocals and the other predicts the Drums. The number of Output layers could be increased based on the number of elements one needs to separate from input Audio Track.
- The entire architecture is built with tensorflow.
- Matplotlib has been used for visualization.
- Numpy has been used for mathematical operations.