A Gentle Introduction to Deep Learning Caption Generation Models
Last Updated on August 7, 2019
Caption generation is the challenging artificial intelligence problem of generating a human-readable textual description given a photograph.
It requires both image understanding from the domain of computer vision and a language model from the field of natural language processing.
It is important to consider and test multiple ways to frame a given predictive modeling problem and there are indeed many ways to frame the problem of generating captions for photographs.
In this tutorial, you will discover 3 ways that you could frame caption generating and how to develop a model for each.
The three caption generation models we will look at are:
- Model 1: Generate the Whole Sequence
- Model 2: Generate Word from Word
- Model 3: Generate Word from Sequence
We will also review some best practices to consider when preparing data and developing caption generation models in general.
Kick-start your project with my new book Deep Learning for Natural Language Processing, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
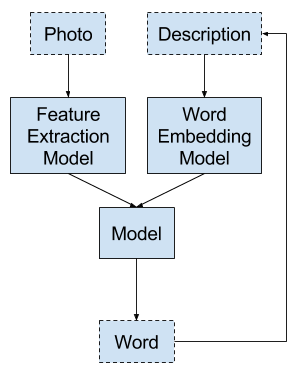
Model 1: Generate the Whole Sequence
The first approach involves generating the entire textual description for the photo given a photograph.
- Input: Photograph
- Output:
To finish reading, please visit source site