A fine-grained manually annotated named entity recognition dataset
Few-NERD
Few-NERD is a large-scale, fine-grained manually annotated named entity recognition dataset, which contains 8 coarse-grained types, 66 fine-grained types, 188,200 sentences, 491,711 entities and 4,601,223 tokens. Three benchmark tasks are built, one is supervised: Few-NERD (SUP) and the other two are few-shot: Few-NERD (INTRA) and Few-NERD (INTER).
The schema of Few-NERD is:
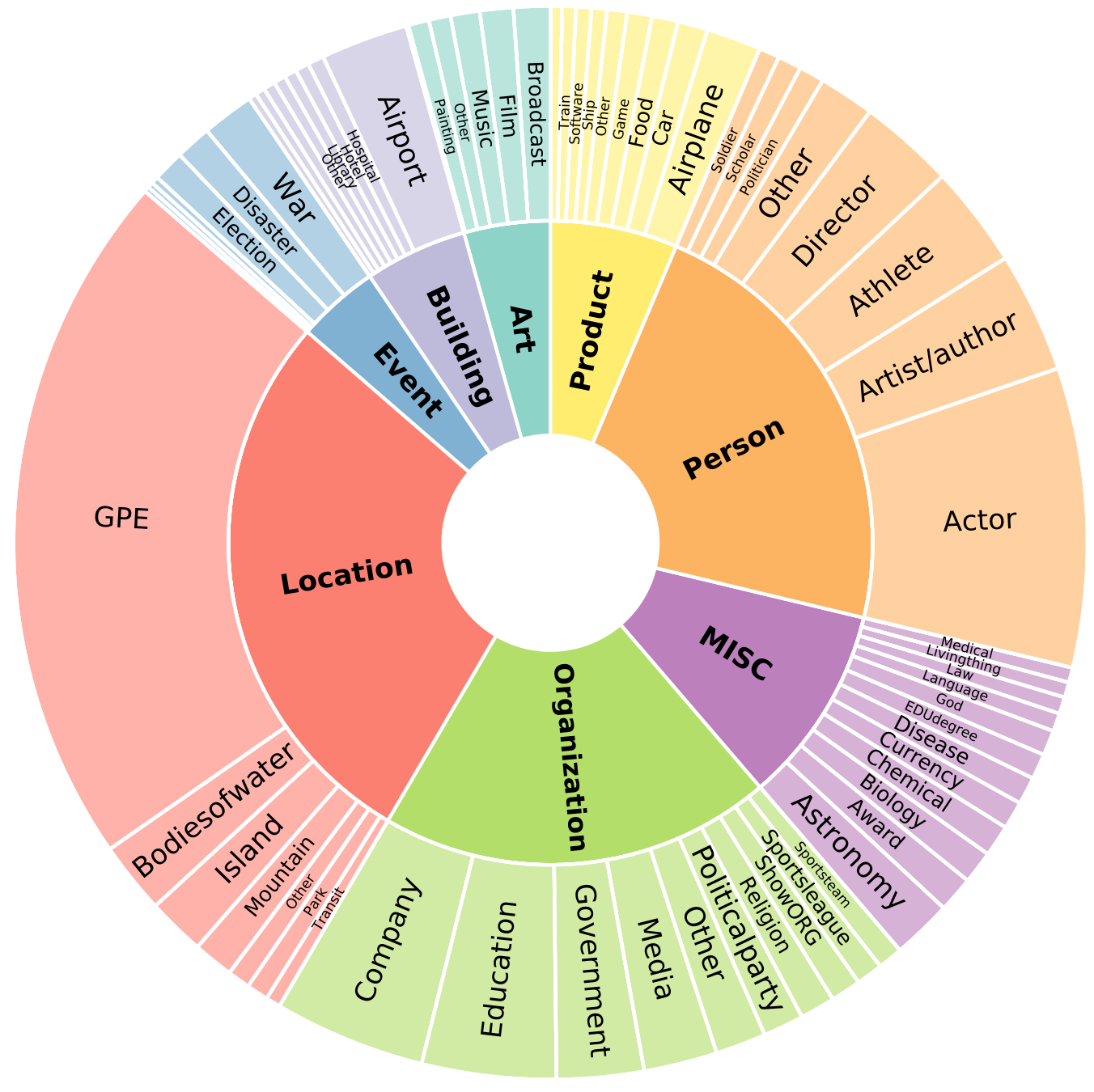
Few-NERD is manually annotated based on the context, for example, in the sentence “London is the fifth album by the British rock band…“, the named entity London is labeled as Art-Music.
Requirements
Run the following script to install the remaining dependencies,
pip install -r requirements.txt
Few-NERD Dataset
Get the Data
- Few-NERD contains 8 coarse-grained types, 66 fine-grained types, 188,200 sentences, 491,711 entities and 4,601,223 tokens.
- We have splitted