Month: October 2021
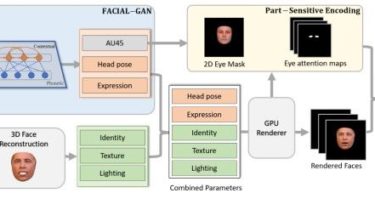
FACIAL: Synthesizing Dynamic Talking Face With Implicit Attribute Learning
PyTorch implementation for the paper: FACIAL: Synthesizing Dynamic Talking Face with Implicit Attribute Learning Chenxu Zhang,Yifan Zhao,Yifei Huang,Ming Zeng,Saifeng Ni,Madhukar Budagavi,Xiaohu Guo ICCV 2021 Run demo on Google Colab Requirements conda create -n audio_face conda activate audio_face sudo apt-get install ffmpeg pip install -r requirements.txt you may add opencv by conda. Citation
Read more
LiteX development baseboard arround the SQRL Acorn
__ _ __ _ __ ___ / / (_) /____ | |/_/___/ _ |_______ _______ / /__/ / __/ -_)>
Read moreAASIST: Audio Anti-Spoofing using Integrated Spectro-Temporal Graph Attention Networks
This repository provides the overall framework for training and evaluating audio anti-spoofing systems proposed in ‘AASIST: Audio Anti-Spoofing using Integrated Spectro-Temporal Graph Attention Networks’ Getting started requirements.txt must be installed for execution. We state our experiment environment for those who prefer to simulate as similar as possible. pip install -r requirements.txt Our environment (for GPU training) Based on a docker image: pytorch:1.6.0-cuda10.1-cudnn7-runtime GPU: 1 NVIDIA Tesla V100 About 16GB is required to train AASIST using a batch size of 24 […]
Read moreGithub dorking tool with python
Supply a list of dorks and, optionally, one of the following: a user (-u) a file with a list of users (-uf) an organization (-org) a file with a list of organizations (-of) a repo (-r) You can also pass: an output directory to store results (-o) a filename to store valid items, if your users or org file may contain nonexistent users/orgs (-vif) All input files (dorks, users, or orgs) should be newline-separated. Usage Clone the repository, then runpip […]
Read moreA configurable set of panels that display various debug information about the current request/response
GitHub – jazzband/django-debug-toolbar: A configurable set of panels that display various debug information about the current request/response. A configurable set of panels that display various debug information about the current request/response. – GitHub – jazzband/django-debug-toolbar: A configurable set of panels that display various d…
Read moreUsing Pygame to Build an Asteroids Game in Python
Do you want to create your own computer games but like Python too much to abandon it for a career as a game developer? There’s a solution for that! With the Pygame module, you can use your amazing Python skills to create games, from the basic to the very complex. Below, you’ll learn how to use Pygame by making a clone of the Asteroids game! In this course, you’ll learn how to build a complete game, including: Loading images and […]
Read more
Dynamic Encoder Transducer: A Flexible Solution For Trading Off Accuracy For Latency
August 30, 2021 By: Yangyang Shi, Varun Nagaraja, Chunyang Wu, Jay Mahadeokar, Duc Le, Rohit Prabhavalkar, Alex Xiao, Ching-Feng Yeh, Julian Chan, Christian Fuegen, Ozlem Kalinli, Michael L. Seltzer Abstract We propose a dynamic encoder transducer (DET) for on-device speech recognition. One DET model scales to multiple devices with different computation capacities without retraining or fine-tuning. To trading off accuracy and latency, DET assigns different encoders to decode different parts of an utterance. We apply and compare the layer dropout […]
Read more
Contrast and Classify: Training Robust VQA Models
Abstract Recent Visual Question Answering (VQA) models have shown impressive performance on the VQA benchmark but remain sensitive to small linguistic variations in input questions. Existing approaches address this by augmenting the dataset with question paraphrases from visual question generation models or adversarial perturbations. These approaches use the combined data to learn an answer classifier by minimizing the standard cross-entropy loss. To more effectively leverage augmented data, we build on the recent success in contrastive learning. We propose a novel […]
Read more
Kaizen: Continuously Improving Teacher Using Exponential Moving Average For Semi-supervised Speech Recognition
To help personalize content, tailor and measure ads, and provide a safer experience, we use cookies. By clicking or navigating the site, you agree to allow our collection of information on and off Facebook through cookies. Learn more, including about available controls: Cookies Policy I Agree
Read more